L'intelligence artificielle (IA) continue de repousser les frontières de ce qui est possible, s'implantant au cœur de défis sociétaux et technologiques majeurs. Loin de se limiter à des applications grand public, les chercheurs explorent des voies innovantes pour rendre l'IA plus robuste, plus autonome et plus alignée avec les valeurs humaines.
Des avancées récentes, publiées sur arXiv, révèlent comment l'IA est désormais capable de mesurer des concepts abstraits comme la paix, de révolutionner l'apprentissage des robots et de doter les modèles de langage d'une logique infaillible. Ces percées dessinent un futur où les systèmes intelligents ne sont pas seulement performants, mais aussi fiables et bénéfiques pour l'humanité.
Plongez au cœur de ces innovations qui redéfinissent notre compréhension et notre interaction avec les machines, ouvrant la voie à des applications autrefois reléguées à la science-fiction.

L'IA au service de la paix et de la compréhension médiatique
L'impact de l'intelligence artificielle ne se limite pas aux laboratoires; elle s'étend désormais à des domaines cruciaux pour la société. Selon une étude de P. Gilda, P. Dungarwal et A. Thongkham (arXiv, 2026), l'apprentissage automatique et l'IA sont utilisés pour des objectifs ambitieux : mesurer les niveaux de paix dans différents pays à partir de données issues des médias d'information et des réseaux sociaux. En employant des réseaux neuronaux sur des intégrations textuelles de sources d'actualités en ligne, ces chercheurs ont développé des outils capables de quantifier cette notion complexe. Plus encore, ils ont créé des plateformes en ligne visant à aider les utilisateurs à mieux comprendre leur propre "régime médiatique", favorisant ainsi une meilleure information et, potentiellement, la paix.
Cette approche novatrice démontre le potentiel de l'IA à analyser des volumes massifs de données textuelles pour en extraire des indicateurs sociétaux, offrant une perspective inédite sur la dynamique des conflits et de la cohésion sociale.
Vers des intelligences artificielles plus robustes et alignées
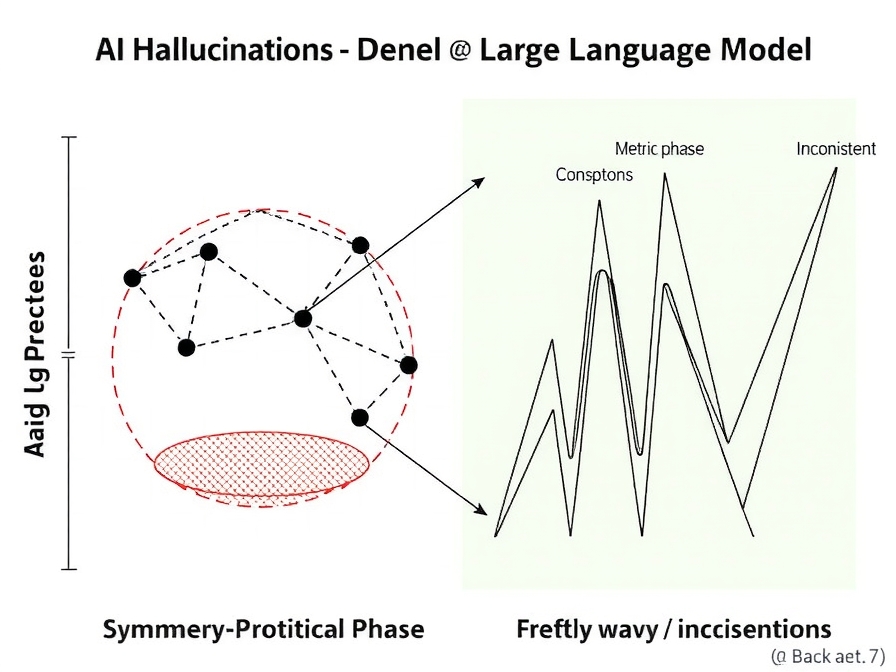
Les modèles de langage de grande taille (LLM) ont montré des capacités impressionnantes, mais ils souffrent encore d'un problème majeur : les "hallucinations", ces inconsistances logiques qui minent leur fiabilité. Pour y remédier, Ilmo Sung (arXiv, 2026) propose une approche révolutionnaire. L'étude suggère que les architectures actuelles opèrent dans une "phase métrique" où l'ordre causal est vulnérable à la rupture spontanée de symétrie. En identifiant l'inférence robuste comme une "phase topologique protégée par la symétrie", où les opérations logiques sont isomorphes à des tressages d'anyons non-abéliens, le chercheur ouvre la voie à des LLM dotés d'un raisonnement intrinsèquement plus fiable et moins sujet aux erreurs.
Parallèlement, alors que les modèles de langage deviennent de plus en plus sophistiqués, les utilisateurs attendent d'eux non seulement des réponses précises, mais aussi des comportements alignés avec des préférences humaines diverses. Pour atteindre cet objectif, les pipelines d'apprentissage par renforcement (RL) intègrent désormais de multiples récompenses, chacune capturant une préférence distincte. Cependant, la complexité de l'optimisation multi-récompenses a posé des défis. Shih-Yang Liu, Xin Dong et Ximing Lu (arXiv, 2026) ont développé le "Group reward-Decoupled Normalization Policy Optimization (GDPO)", une méthode qui optimise l'apprentissage par renforcement multi-récompenses, permettant aux modèles de mieux s'aligner avec un éventail plus large de préférences humaines. Cette avancée est cruciale pour créer des IA plus éthiques et utiles dans des scénarios complexes.

Révolutionner la robotique et l'apprentissage autonome
La formation des robots nécessite une quantité et une qualité de données de manipulation considérables, mais leur collecte dans le monde réel est souvent limitée par des contraintes matérielles. Pour surmonter cet obstacle, Boyang Wang, Haoran Zhang et Shujie Zhang (arXiv, 2026) présentent "RoboVIP", une méthode de génération de vidéos multi-vues avec "visual identity prompting". Cette technique utilise des modèles de diffusion d'images conditionnés par du texte pour augmenter les données de manipulation en modifiant les arrière-plans et les objets, offrant aux robots des scénarios d'entraînement diversifiés sans avoir besoin de manipulations physiques coûteuses. Cela ouvre la porte à des politiques robotiques plus efficaces et généralisables.
En complément, pour que les agents puissent raisonner et planifier efficacement dans le monde réel, ils doivent être capables de prédire les conséquences de leurs actions. C'est le rôle des "modèles du monde". Cependant, ces modèles requièrent souvent des étiquettes d'action explicites, difficiles à obtenir à grande échelle. Quentin Garrido, Tushar Nagarajan et Basile Terver (arXiv, 2026) abordent ce problème en proposant d'apprendre des "modèles du monde à action latente" à partir de simples vidéos. Cette approche permet aux agents de déduire un espace d'action implicite et de prédire les résultats de leurs choix sans intervention humaine directe, marquant une étape majeure vers des agents autonomes capables de comprendre et d'interagir avec leur environnement de manière plus naturelle.
Implications et perspectives
Ces récentes découvertes en intelligence artificielle promettent de transformer en profondeur de nombreux secteurs. Des systèmes d'IA capables de mesurer la paix et de promouvoir une consommation médiatique éclairée pourraient jouer un rôle clé dans la diplomatie et la prévention des conflits. Des modèles de langage plus robustes et alignés sur des préférences humaines complexes signifieraient des assistants virtuels plus fiables, des outils de création de contenu plus éthiques et une meilleure interaction homme-machine.
Dans le domaine de la robotique, la capacité à générer des données d'entraînement synthétiques de haute qualité et à permettre aux robots d'apprendre des modèles du monde à partir de simples observations ouvre la voie à une nouvelle génération de machines autonomes, capables de s'adapter et d'opérer dans des environnements complexes avec une agilité sans précédent. Ces avancées préfigurent un avenir où l'IA ne sera pas seulement un outil, mais un partenaire intelligent et fiable pour relever les plus grands défis de notre temps.
Faits marquants
- L'IA peut désormais mesurer les niveaux de paix dans les pays à partir de l'analyse des médias et des réseaux sociaux (P. Gilda et al., arXiv, 2026).
- De nouvelles théories proposent de combattre les "hallucinations" des LLM en les faisant opérer dans une "phase topologique protégée par la symétrie" pour un raisonnement robuste (I. Sung, arXiv, 2026).
- L'optimisation par renforcement multi-récompenses (GDPO) permet aux modèles de langage de mieux s'aligner avec les diverses préférences humaines (S.-Y. Liu et al., arXiv, 2026).
- "RoboVIP" utilise la génération de vidéos multi-vues pour augmenter la quantité et la qualité des données d'entraînement pour la manipulation robotique (B. Wang et al., arXiv, 2026).
- Les "modèles du monde à action latente" permettent aux agents d'apprendre les conséquences de leurs actions à partir de vidéos seules, sans étiquettes explicites (Q. Garrido et al., arXiv, 2026).
Sources et références
- Measuring and Fostering Peace through Machine Learning and Artificial Intelligence (2026-01-08)
- GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization (2026-01-08)
- RoboVIP: Multi-View Video Generation with Visual Identity Prompting Augments Robot Manipulation (2026-01-08)
- Robust Reasoning as a Symmetry-Protected Topological Phase (2026-01-08)
- Learning Latent Action World Models In The Wild (2026-01-08)